Deep Neural Network
Deep neural network atau DNN merupakan topik penelitian yang sedang booming belakangan ini. DNN sebenarnya bukan merupakan sebuah field baru pada Ilmu Komputer. Penelitian dan penerapan DNN sudah dimulai dari tahun 90-an. Akan tetapi perkembangan algoritma untuk men-train DNN dan hardware untuk komputasi belum memupuni pada saat tersebut.
Deep Neural Network dapat digambarkan sebagai Multilayer Perceptron dengan hidden layer lebih dari dua, dimana struktur model dapat terdiri dari berbagai jenis network. Kesuksesan DNN pada saat ini didukung oleh berbagai faktor yang meliputi:
- Penemuan-penemuan teknik komputasi dalam mentrain DNN seperti Glorot weight initialization, fungsi aktivasi ReLu, dan optimisasi algoritma Adam.
- Perkembangan hardware Graphic Processing Unit (GPU) yang memungkinkan proses komputasi matematika secara paralel lebih cepat dibanding CPU.
- Tersedianya public dataset degan jumlah yg cukup besar untuk mentrain DNN.
DNN dan Neurocortex
Neurocortex
Neocortex merupakan bagian dari otak manusia yang memungkinkan manusia untuk beradaptasi dengan kondisi sekitar dengan cepat. Neocortex sendiri merupakan hasil evolusi untuk bertahan hidup dan bereproduksi yang hanya terdapat pada mamalia. Oleh karena itu, mamalia seperti anjing, simpanse, dan manusia dapat beradaptasi dengan kondisi lingkungan secara cepat.
Pada otak manusia neurocortex memiliki porsi terbesar dibanding bagian otak lainnya. Fungsi utama neurocortex adalah pattern recognition yang berkerja secara hirarikal. Cell pada setiap level neurocortex memiliki fungsi yang berbeda, dimana cell pada level yang lebih tinggi memiliki kemampuan untuk mengenali pola yang lebih abstrak.
Cell-cell pada neurocortex akan aktif ketika menerima inputan yang dikenalinya dan akan mengirimkan sinyal kepada cell-cell yang berada pada level yang lebih tinggi. Lebih dari itu, cell-cell yang aktif bersamaan berdasarkan suatu input akan terhubung dan memiliki koneksi yang lebih kuat satu sama lain (Hebbian learning). Proses pembelajaran terjadi tidak pada cell-cell tersebut akan tetapi pada weight atau koneksi yang menghubungkan cell-cell.
FYI: neuroceortex memiliki tingkat false postif (FP) yang lebih besar dibandingkan dengan false negatif (FN). FP adalah sebuah hasil yang mengindikasikan bahwa suatu kondisi terpenuhi ketika sebenarnya kondisi tersebut tidak terpenuhi. Sedangkan FN adalah sebuah hasil yang mengindikasikan bahwa suatu kondisi tidak terpenuhi ketika sebenarnya terpenuhi. Hal ini menyebabkan kita sebagai manusia sering menganggap gerakan pada semak-semak yang diakibatkan oleh angin adalah gerakan binatang buas. Akan tetapi kita tidak pernah menggagap binatang buas sebagai angin. Dan hal ini juga yang mengakibatkan banyak dari umat manusia yang melihat muka Nabi ataupun pemimpin agamanya pada awan atau lautan. Akan tetapi tidak pernah melihat awan atau lautan pada muka Nabi ataupun pemimpin agamanya.
DNN
Pada dasarnya Aritificial Neural Network (ANN) dan DNN mengadaptasi prinsip kerja Neurocortex dalam merepresentasikan data. Pada setiap layer DNN terdapat neuron(cell) yang akan aktif ketika menerima input yang sesuai dan akan mengirimkan sinyal terhadap neuron pada layer selanjutnya. Dimana weight yang menghubungkan neuron pada layer lebih rendah dan layer lebih tinggi akan memiliki nilai yang lebih besar jika neuron tersebut aktif secara bersamaan untuk input yang diberikan. Contoh: dalam proses training ketika input masukan adalah kata apel maka neuron yang mengenali kata a dan p akan aktif dan nilai weight yang menghubungkan neuron tersebut menjadi lebih besar dibandingkan dengan denga neuron yang mengenali kata lain seperti anggur dan pisang pada layer selanjutnya.
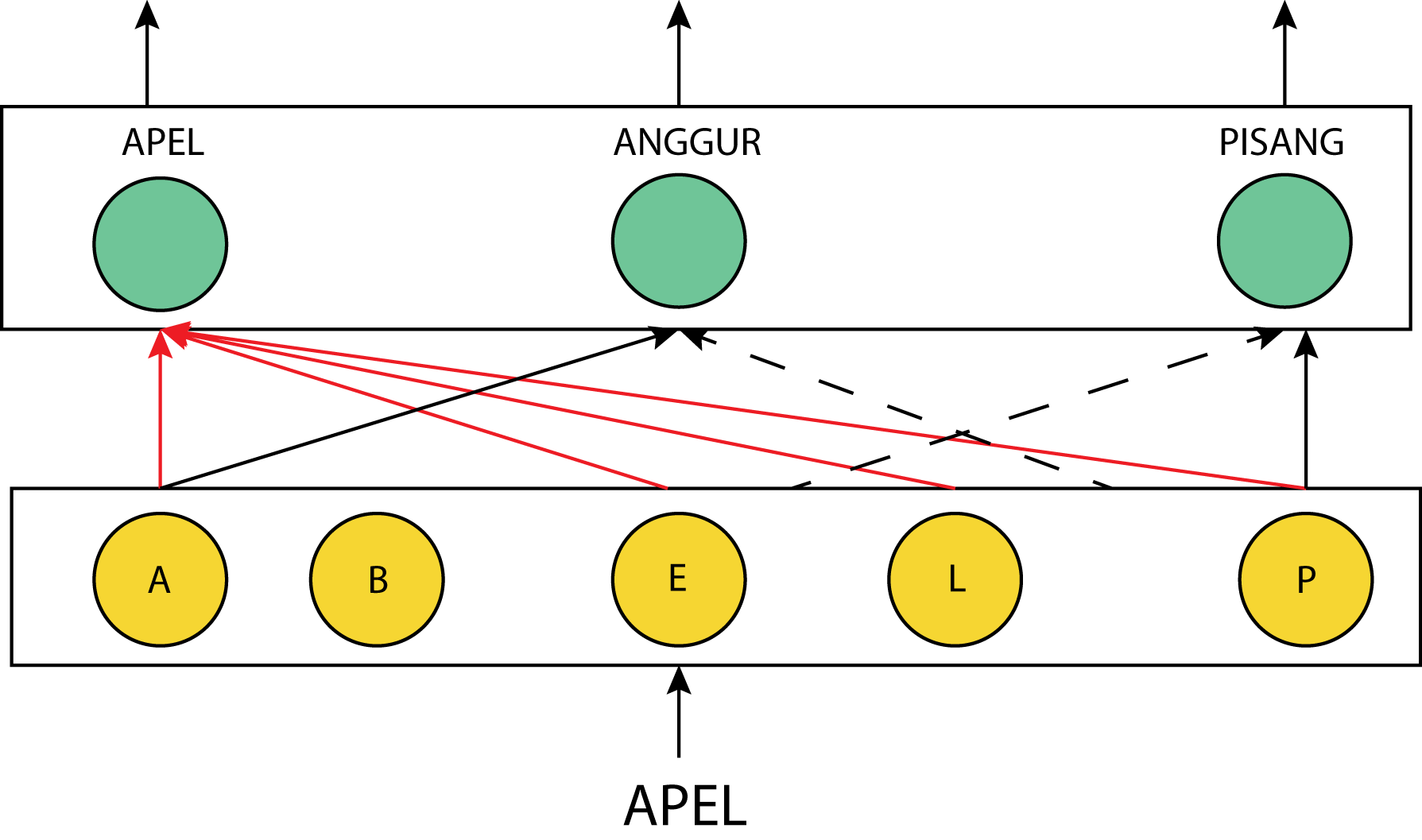
Walaupun DNN terinspirasi dan mengadaptasi konsep neurocortex akan tetapi hingga saat ini masih terdapat perbedaan dalam teknik komputasi DNN dan neurocortex. Pada umumnya DNN mengadopsi teknik bottom-up dimana neuron layer lebih rendah akan mengirim sinyal kepada neuron pada layer lebih tinggi berdasarkan input yang diberikan. Sedangkan pada neurocortex tidak hanya cell pada level lebih rendah mengirimkan sinyal kepada cell pada level lebih tinggi akan tetapi cell lebih tinggi juga dapat mengirimkan sinyal kepada cell lebih rendah. Sehingga neurocortex dapat dikatakan mengadopsi konsen bottom-up dan top-down. Sebagai contoh: ketika inputan apel diberikan maka cell yang mengenali karakter a dan p akan mengirimkan sinyal kepada cell yang mengenali kata apel pada level yang lebih tinggi. Setelah itu, cell yang mengenali kata apel akan mengirim sinyal kepada cell di level yang lebih rendah untuk mengenali kata e.
DNN sebagai Representation Learning
Berbeda dengan teknik konvensional Machine Learning seperti Support Vector Machine (SVM) atau Hidden-Markov-Model yang membutuhkan expert-designed features extractor untuk mentransform raw-data menjadi informative features sebelum proses learning. DNN menerapkan konsep representation-learning, yang memungkinkan DNN untuk secara langsung menemukan dan merepresentasikan patttern pada data.
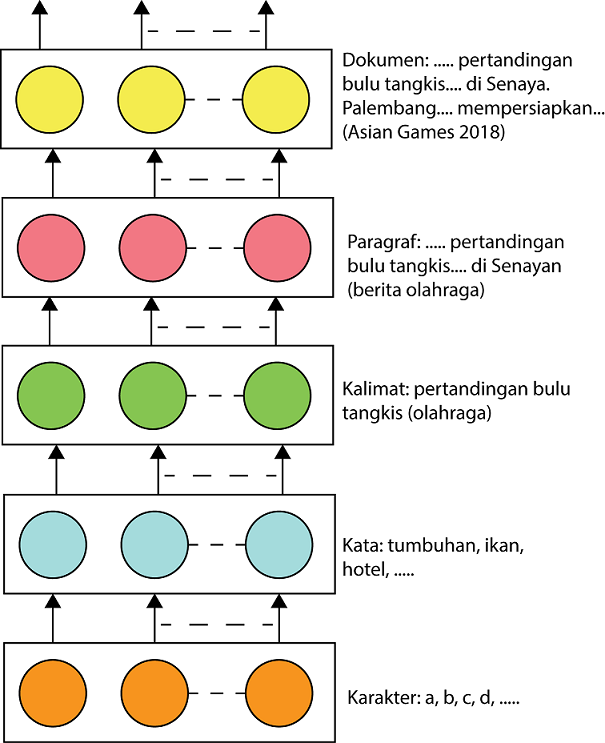
Pada DNN setiap layer memiliki level of abstraction yang berbeda, semakin dalam sebuah layer semakin kompleks abstraksi yang layer tersebut dapat representasikan. Sebagai contoh: untuk sebuah DNN model dengan lima layer digunakan untuk mengklasiikasi sebuah dokumen. Layer pertama dapat digambarkan memiliki peran untuk men-recognize karakter. Layer kedua, ketiga, dan keempat dapat mengenali kata, kalimat, dan paragraf. Sedangkan layer terakhir dapat mengklasifikasikan kumpulan paragraf yang bersangkutan.
Tipe Neural Network
Feed-Forward Neural Network
Feed-forward NN merupakan tipe neural-network dimana setiap neuron pada layer \(i\) dihubungkan oleh weight dengan seluruh neuron pada layer selanjutnya \(i+1\).
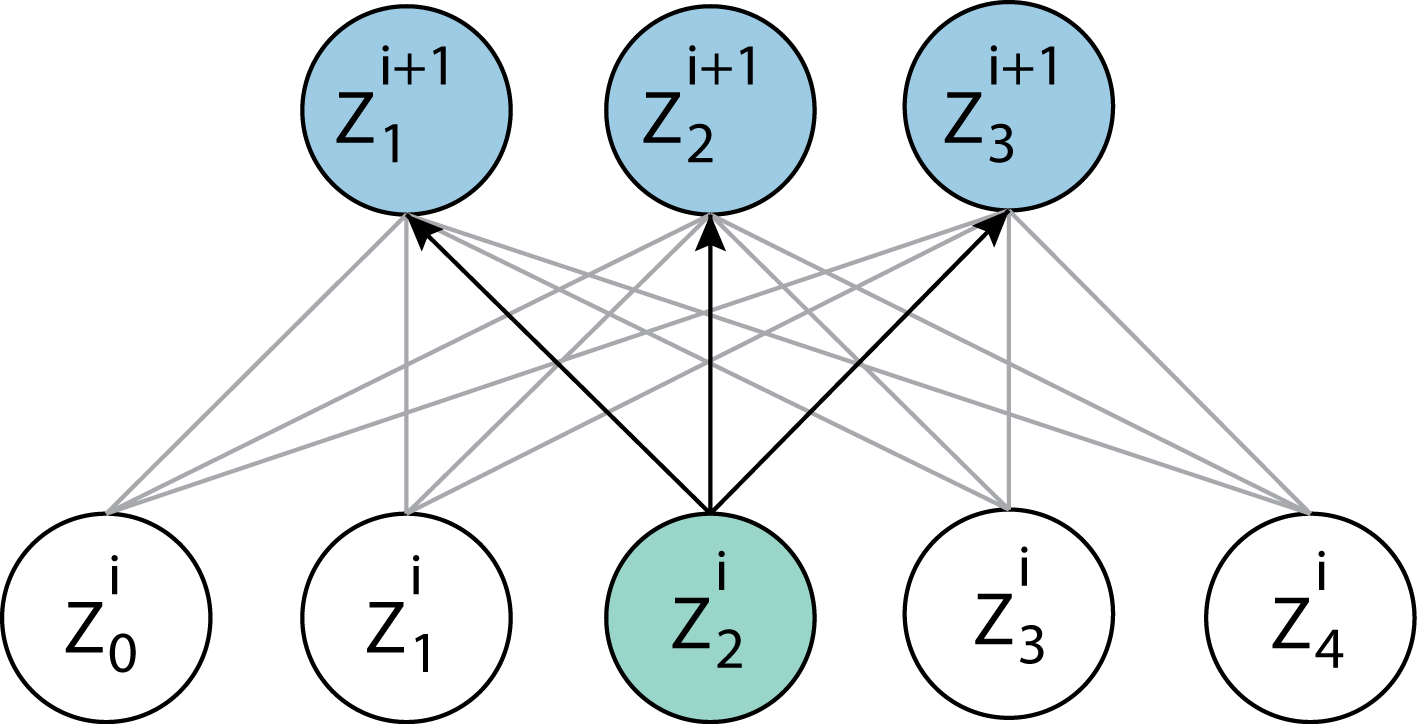
Untuk neuron \(Z^{i} = \{ z_0, z_1, \cdots, Z_M \}\) dan weights \(W^{i} = \{ w_{0,0}, w_{0, 1}, \cdots, w_{N,M} \}\) feed forward neural network dapat diformulasikan sebagai berikut
\[Z^{i+1} = f(Z^{i} * W^{i})\]Convolutional Neural Network
Convolutional neural network adalah tipe neural network yang mengaplikasikan convolution operator untuk mengekstrak fitur dari sebuah input. Convolution operator dengan input berdimensi \((1, t)\) dituliskan dengan
\[F(t) = (I \ast W)(t) = \int_{-\infty}^{\infty} I(a)W(t-a) da\]dimana \(I\) adalah input dan \(W\) adalah weights atau disebut kernel. Sedangkan, untuk sebuah input discrete, convolution operator dituliskan dengan formula
\[F(t) = \sum_{-\infty}^{\infty}I(a)W(t - a)\]Pada pengaplikasiannya, input untuk convolution operator bisa memiliki dimensi lebih besar dari pada satu. Contoh, penerapan convolution operator pada sebuah gambar yang dapat dirumuskan dengan
\[F(x, y) = (I \ast W) (x, y) = \sum_{m} \sum_{n} I(x, y)W(x-m, y-n)\]Walaupun secara teori convolutional neural network menerapakan convolution operator, banyak deep neural network library yang menggunakan cross-correlation operator untuk menghitung output convolutional neural network.
\[F(t) = \sum_{a}I(t+a)W(a)\]Perhitungan Cross-Correlation dengan Tensorflow
Pada Tensorflow, untuk input \(I\) dan kernel \(W\) yang berdimensi satu, convolution \((I \ast W)(t)\) dapat dihitung menggunakan fungsi tf.nn.conv1d. Pada fungsi tf.nn.conv1d kita dapat menentukan apakah kita akan melakukan penambahan elemen pada input atau tidak dengan men-set nilai variable padding. padding=”SAME” mengindikasikan penambahan nilai 0 pada sisi kiri dan kanan \(I\) dengan jumlah yang sama, jika jumlah elemen \(I\) adalah ganjil penambahan hanyan akan dilakukan pada bagian kanan. Pada implementasi kode dibawah ini, nilai padding=”SAME” dan nilai stride=1 (pergeseran filter sebanyak 1 elemen), sehingga jumlah elemen output sama dengan jumlah elemen input, \(|F|=|I|\).
Untuk \(I = \{4, 1, 2, 5 \}\) dan \(W=\{1, 2, -1 \}\), nilai \(F\) adalah
import tensorflow as tf
tf.enable_eager_execution()
I = tf.expand_dims(tf.constant(value=[[4, 1, 2, 5]], dtype=tf.float32), -1)
W = tf.expand_dims(tf.constant(value=[[1], [2], [-1]], dtype=tf.float32), -1)
F = tf.nn.conv1d(I, W, stride = 1, padding="SAME", data_format="NWC", use_cudnn_on_gpu=False)
, dimana F bernilai \({7., 4., 0., 12.}\) yang dapat dijabarkan dengan perhitungan dibawah ini
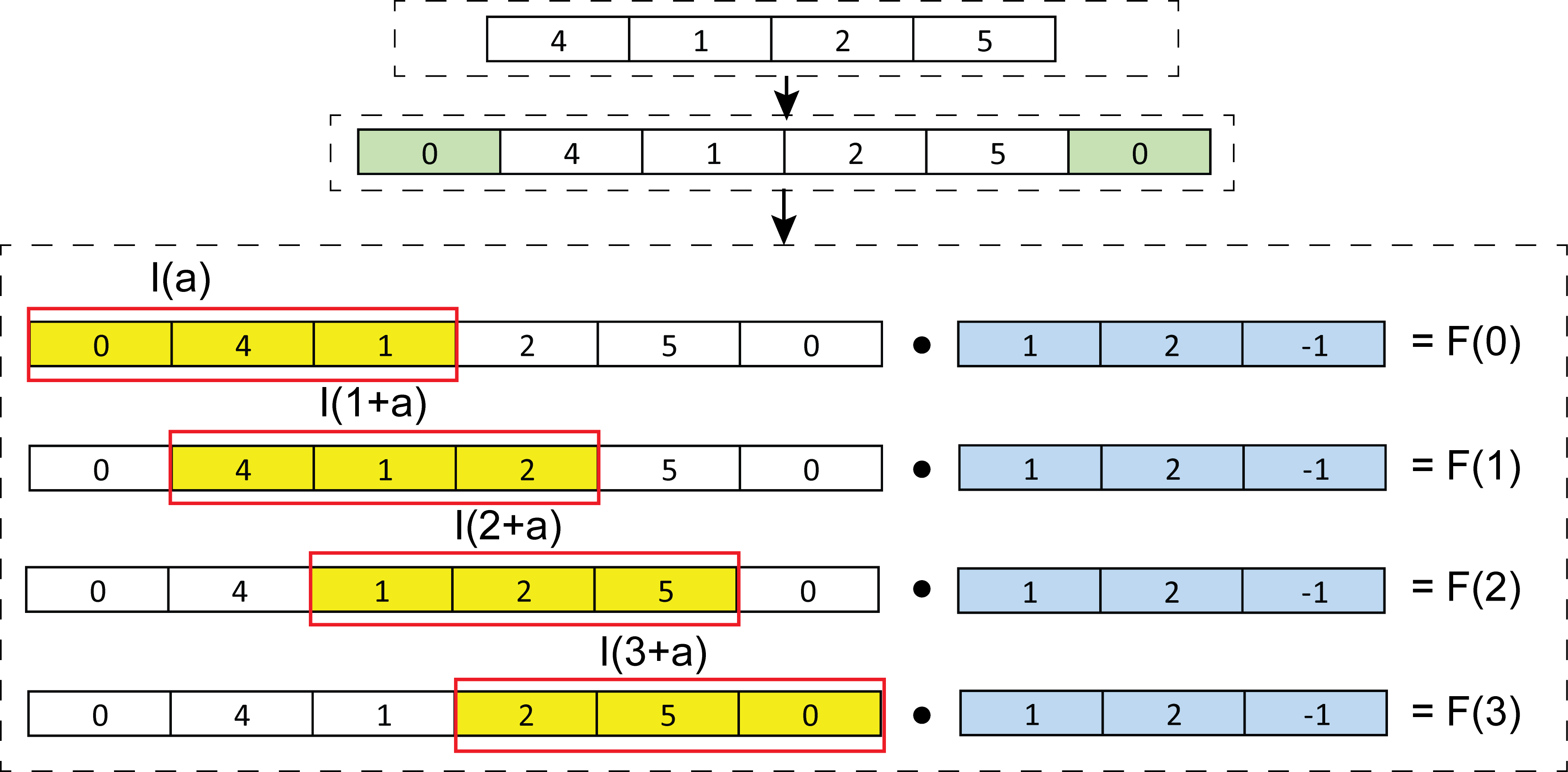
Untuk
\[F(0) = \sum_{a}I(a)W(a) = 0 \cdot 1 + 4 \cdot 2 + 1 \cdot -1 = 7\] \[F(1) = \sum_{a}I(1+a)W(a) = 4 \cdot 1 + 1 \cdot 2 + 2 \cdot -1 = 4\] \[F(2) = \sum_{a}I(2+a)W(a) = 1 \cdot 1 + 2 \cdot 2 + 5 \cdot -1 = 0\] \[F(3) = \sum_{a}I(3+a)W(a) = 2 \cdot 1 + 5 \cdot 2 0 \cdot -1 = 12\]Untuk input dua dimensi, perhitungan convolution menggunakan Tensorflow dilakukan dengan menggunakan fungsi tf.nn.conv2d. Pada implementasi kode dibawah ini, convolution operator diterapkan pada input dengan nilai \(I = \begin{bmatrix} 4 & 5 & -1 \\ 3 & 2 & 1 \\ 1 & 7 & 8 \end{bmatrix}\) dan kernel dengan nilai \(W = \begin{bmatrix} -1 & 2 \\ -2 & 1 \end{bmatrix}\)
I = tf.expand_dims(tf.constant(value=[[[4, 5, -1], [3, 2, 1], [1, 7, 8]]], dtype=tf.float32), -1)
W = tf.expand_dims(tf.expand_dims(tf.constant(value=[[-1, 2], [-2, 1]], dtype=tf.float32), -1), -1)
F = tf.nn.conv2d(I, W, strides=[1, 1, 1, 1], padding="SAME", data_format="NHWC", use_cudnn_on_gpu=False)
Dimana \(F\) bernilai \(\begin{bmatrix} 2. & -10. & -1. \\ 6 & -6. & -17. \\ 13. & 9. & -8. \end{bmatrix}\) dapat dijabarkan dengan perhitungan dibawah ini
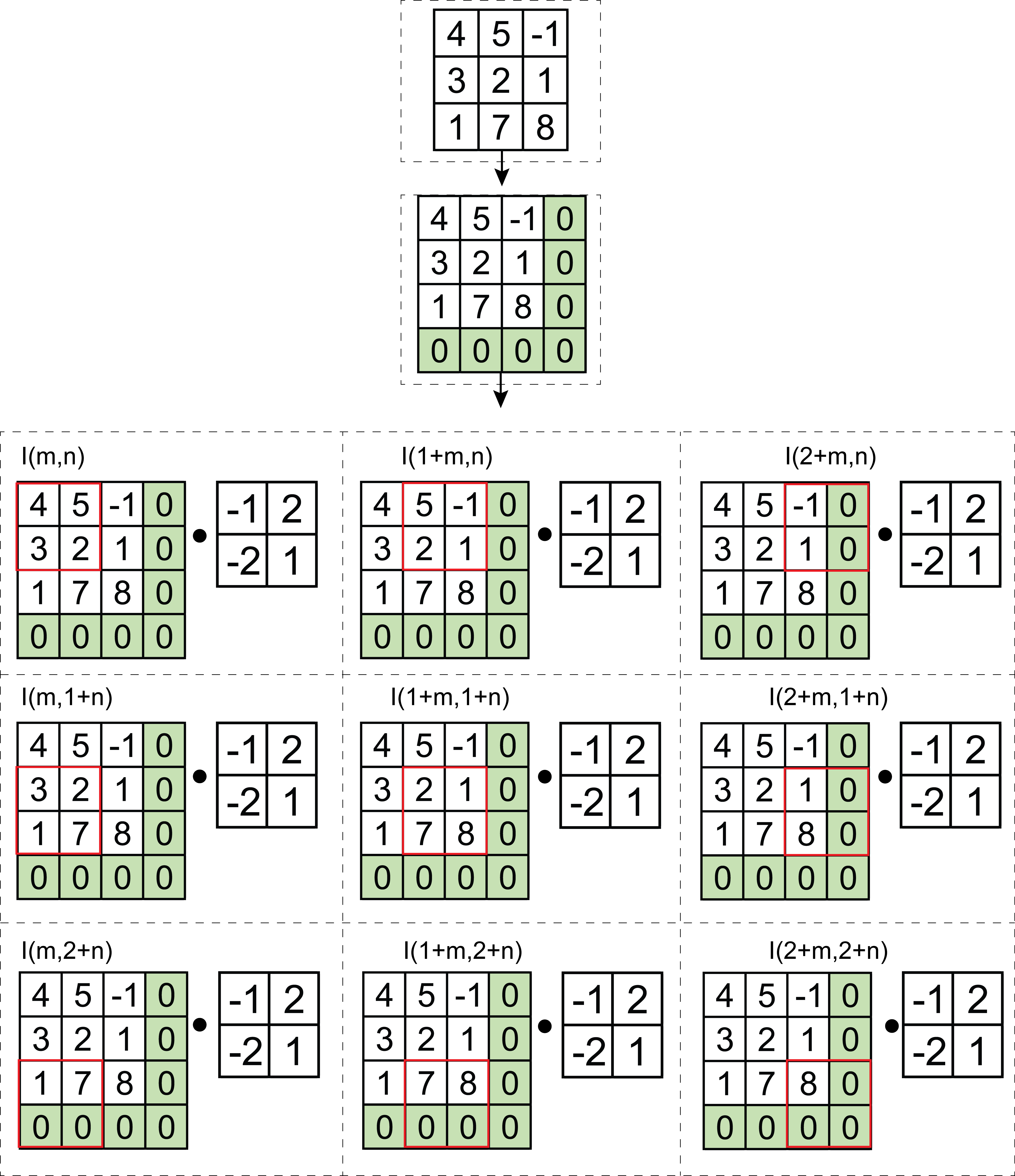
Untuk
\[F(0, 0) = \sum_{m}\sum_{n}I(m, n)W(m, n) = 4 \cdot -1 + 3 \cdot -2 + 5 \cdot 2 + 2 \cdot 1 = 2\] \[F(1, 0) = \sum_{m}\sum_{n}I(1+m, n)W(m, n) = 5 \cdot -1 + 2 \cdot -2 + 1 \cdot 2 -1 \cdot 1 = -10\] \[\vdots\] \[F(1, 2) = \sum_{m}\sum_{n}I(m, n)W(m, n) = 7 \cdot -1 + 0 \cdot -2 + 8 \cdot 2 + 0 \cdot 1 = 9\] \[F(2, 2) = \sum_{m}\sum_{n}I(1+m, n)W(m, n) = 8 \cdot -1 + 0 \cdot -2 + 0 \cdot 2 -1 \cdot 0 = -8\]Recurrent Neural Network
Recurrent neural network adalah tipe neural network yang dapat memproses input berupa sequence, \(X = {x^{(0)}, x^{(i)}, \cdots, x^{(T)}}\). Serupa dengan CNN, RNN juga meaplikasikan sharing-weight, dimana untuk memproses input pada setiap waktu digunakan weight yang sama. Konsep parameter sharing memungkinkan RNN untuk memproses input dengan panjang yang berbeda. Hal ini sangat berguna ketika panjang input pada data test berbeda dengan panjang input pada data training.
Secara umum, neural network dengan fungsi recurrence dapat dikategorikan sebagai RNN. Dimana current state dipengaruhi oleh previous state dan mempengaruhi future state.
\[h^{(t)} = f(h^{(t-1)}, x^{(t)}; \theta)\]RNN sebagai Unfolding Computational Graph
RNN juga dapat direpresentasikan sebagain unfolding computational graph. Dimana sebuah fungsi yang sama digunanakan untuk meproses input sequence. Unfolded RNN dapat dituliskan dengan formula dibawah ini
\[h^{(t)} = g^{(t)}(x^{(t)}, x^{(t-1)}, \cdots, x^{(1)}, x^{(0)})\]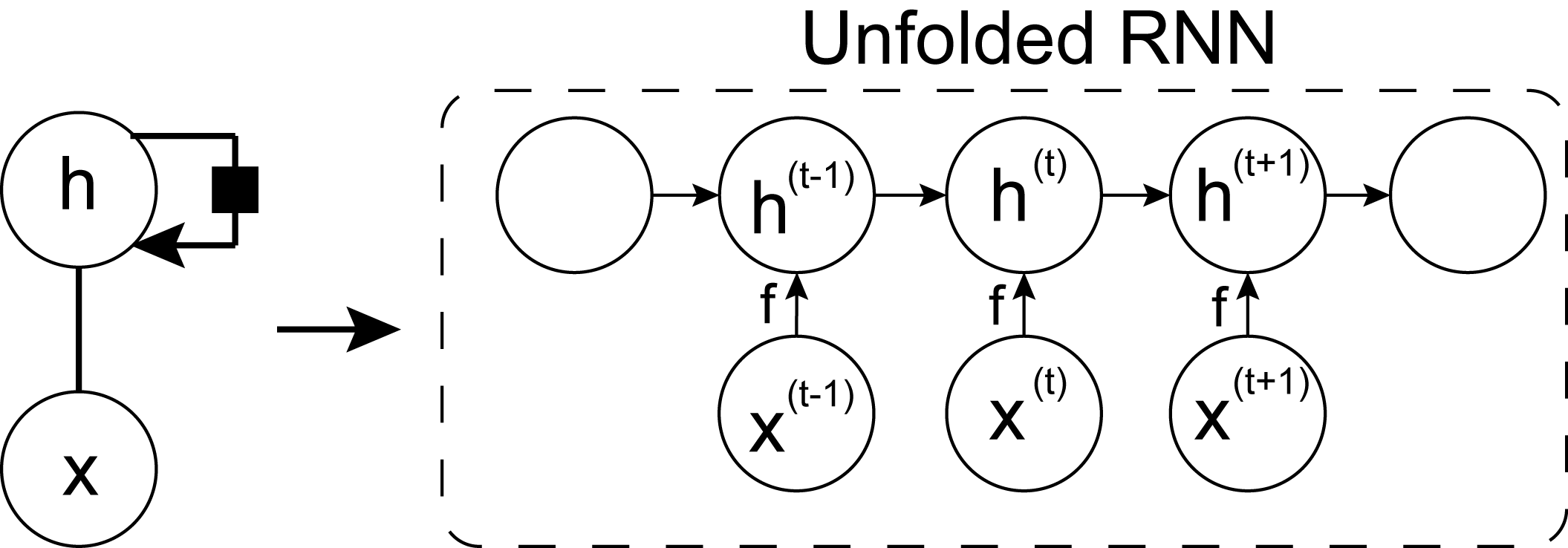
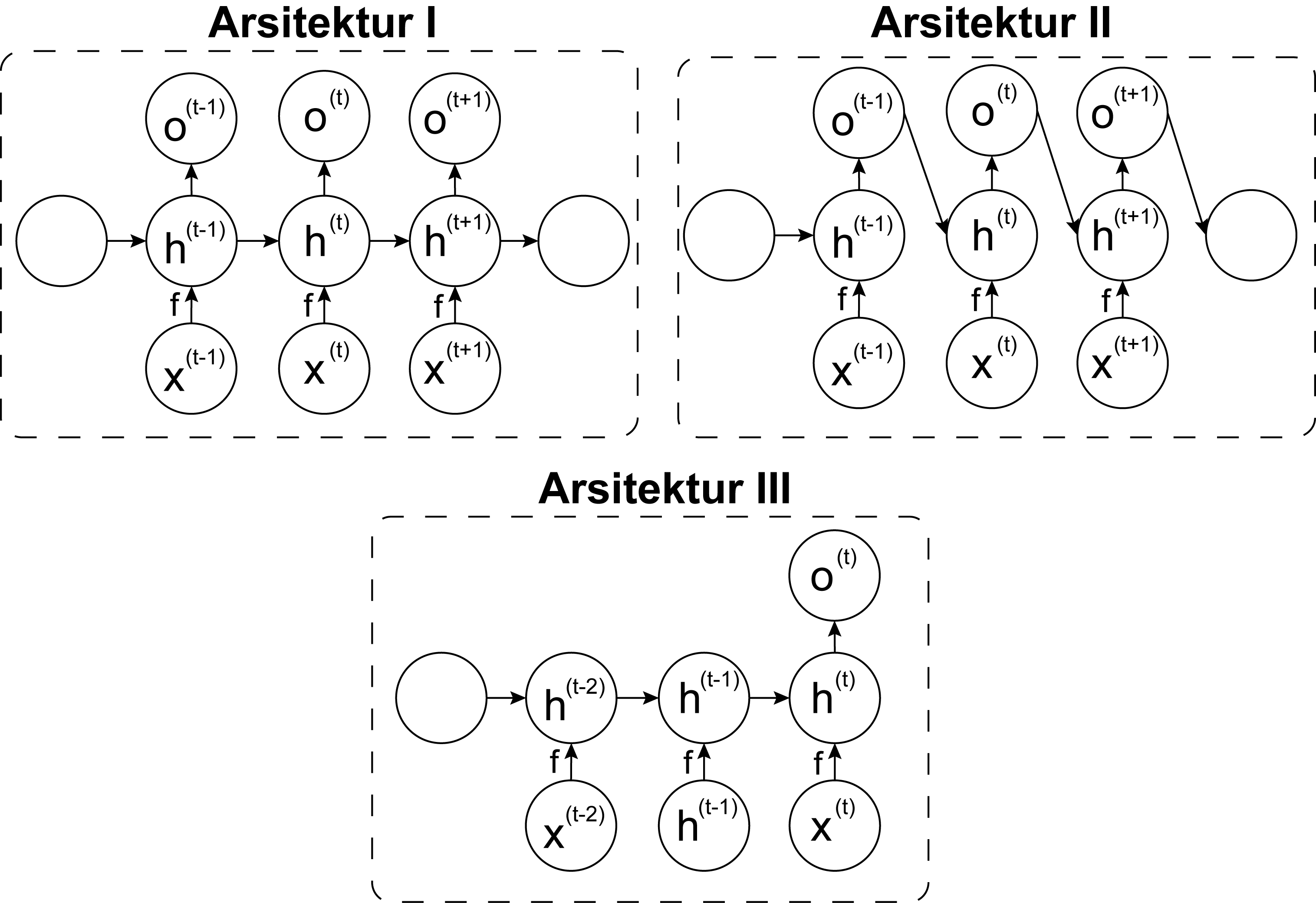
Konsep unfolded RNN memungkinkan penggunaan RNN dengan tiga arsitektur yang berbeda.
Tiga arsitektur RNN:
- Multiple inputs dan outputs dengan recurrent connection diantara hidden units.
- Multiple inputs dan outputs dengan recurrent connection diantara output RNN pada \(t\) time-step dengan hidden unit pada \(t+1\) time-step.
- Multiple inputs dan single unit dengan recurrent connection diantara hidden units.
Referensi
- Goodfellow, I., Bengio, Y. and Courville, A., 2016. Deep learning. MIT press.