Dalam mengevaluasi generalisai performa sebuah Machine Learning ada beberapa teknik yang dapat digunakan seperti: i. training dan testing; ii. k-fold cross validation.
Training and Testing
Training dan testing adalah salah satu teknik dalam mengevaluasi machine learning algoritma. Dalam teknik ini data akan dibagi menjadi dua bagian, training dan testing, dengan proposi 60:40 atau 80:20. Pada teknik ini distribusi untuk pada data harus uniform.
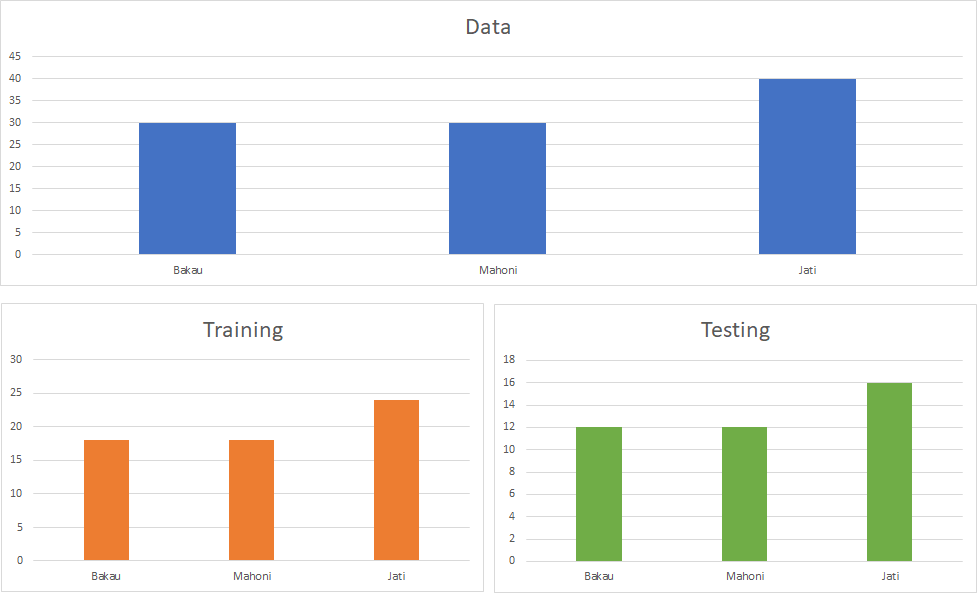
Contoh: Jika kita memiliki data mengenai jenis tumbuhan tropis pada suatu wilayah, dimana pada data tersebut tedapat 3 jenis tumbuhan: bakau(30 data), mahoni (30 data), dan jati (40 data). Total data adalah 100. Jika kita ingin membagi data training dat testing dengan proposi 60:40. Maka untuk data training: bakau (18 data), mahoni (18 data), dan jati (24 data). Sedangkan untuk data testing: bakau (12 data), mahoni (12 data) dan jati (16 data).
Setelah membagi data menjadi dua bagian, training dan testing, machine learning akan di-trained hanya dengan data training. Sedangkan data testing akan digunakan untuk mengevaluasi generalisasi performa dari data tersebut.
Walaupun teknik training dan testing cukup sederhana dan mudah untuk diimplementasi namun ada satu kelemahan dari teknik ini. Jika jumlah data tidak cukup banyak akan tetapi variansi dari data cukup tinggi maka akan ada bias pada hasil evaluasi. Oleh karena itu untuk meminimalisir bias pada hasil evaluasi beberapa peneliti menggunakan K-fold cross validasi.
K-Fold Cross Validation
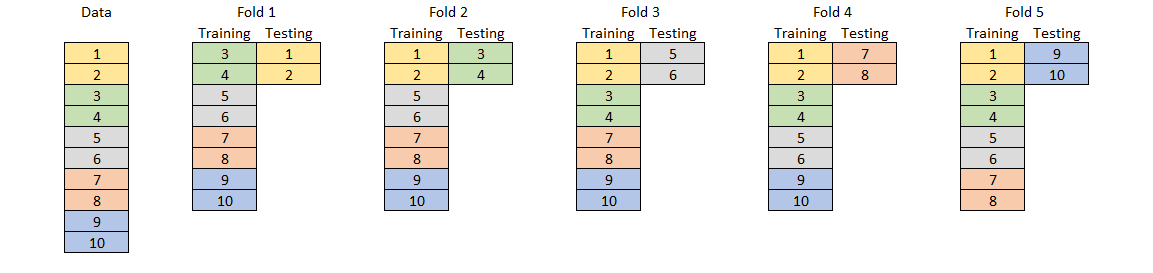
Serupa dengan teknik evaluasi training dan testing, pada K-fold cross validation data akan dibagi menjadi dua bagian: training dan testing; atau tiga bagian: training, validation, dan testing. Akan tetapi, pada teknik K-fold cross validation proses pembagian training dan testing akan dilakukan sebanyak K.
Contoh: Untuk data tanaman tropis diatas, jika kita melakukan 5-fold cross validation. Dimana untuk setiap fold, data akan dibagi dengan proposi 80:20. Maka,
- Fold pertama data training: bakau (24 data), mahoni (24 data), dan jati (32 data); data testing: bakau (6 data), mahoni (6 data) dan jati (8 data).
- Fold pertama data training: bakau (24 data), mahoni (24 data), dan jati (32 data); data testing: bakau (6 data), mahoni (6 data) dan jati (8 data). Dimana data training adalah bagian dari data training + data testing dari fold pertama. Sedangkan data testing adalah bagian dari data training fold pertama.
- dan seterusnya
Pada teknik k-fold cross validation hasil validasi memiliki tingkat bias yang lebih rendah, dikarenakan algoritma ML dievaluasi pada kasus yang berbeda-beda. Namun untuk jumlah data yang cukup besar teknik ini tidak efisien dikarenakan akan memakan waktu yang cukup lama.
Implementasi pada Python
Implementasi training dan testing validation
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
#N = jumlah data
N = 100
#X = features
#generate random data dengan dimensi (N, 5)
X = np.random.rand(N, 5)
#y = labels (0 = bakau, 1 = mahoni, 2 = jati)
#generate data dengan nilai 0, 1, dan 2 dengan proposi 30%, 30%, 40%
y = np.zeros(N)
y[0:30] = 0
y[30: 60] = 1
y[60: 100] = 2
#split data dengan proposi training = 60% dan testing = 40
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.4, stratify=y)
Implementasi K-fold cross validation dengan nilai K = 5
import numpy as np
from sklearn.model_selection import StratifiedShuffleSplit
import matplotlib.pyplot as plt
#N = jumlah data
N = 100
#X = features
#generate random data dengan dimensi (N, 5)
X = np.random.rand(N, 5)
#y = labels (0 = bakau, 1 = mahoni, 2 = jati)
#generate data dengan nilai 0, 1, dan 2 dengan proposi 30%, 30%, 40%
y = np.zeros(N)
y[0:30] = 0
y[30: 60] = 1
y[60: 100] = 2
sss = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=None)
for trainingIndex, testingIndex in sss.split(X, y):
X_train = X[trainingIndex, :]
y_train = y[trainingIndex]
X_test = X[testingIndex, :]
y_test = y[testingIndex]